

UGeek大咖说第10期圆满结束,此次活动特邀到中国联通软件研究院产品线负责人——曹家豪做客直播间,为大家带来《云原生下的数字化实时监控体系建设》的分享,帮助企业走上更顺畅的云原生之旅。
曹老师围绕中国联通在数字化转型后,所面对过的云原生、大规模和分布式的挑战,介绍了从横向到边,从纵向到底的全链路监控管理体系落地实践,以及不同层级监控工具的建设和串联思路,并且还详细解读了故障压降,安全生产保障,以及系统稳定性提升的建设历程。
精彩内容-回顾
云原生下的痛点
现在很多企业在做就是数字化转型的过程中,包括在做云原生的时候,可能都会面临因为i t系统的复杂度的提升而显露一些问题。下面几点是我在做这个变迁过程中所遇到的几个主要的挑战:

2017年天眼平台正式投入建设,旨在打造全集团统一的全层级、全流程、端到端的数字化监控平台支撑,实现自动化生产,智慧化运营。
我们在做这建设时,一般会建很多工具去解决不同场景或层次的问题,针对不同渠道的告警管理也是一个问题,面对这么多的问题和挑战,我们是怎么去解决的?面对监控管理体系的建设,还是需要一些先进可落地的理论作为支撑。接下来我给大家介绍一下,我们的建设理论。对于体系的建设,主要是遵循了谷歌的MTTR,我们在这套理论的基础上进行了一些扩充。
监控体系建设思路
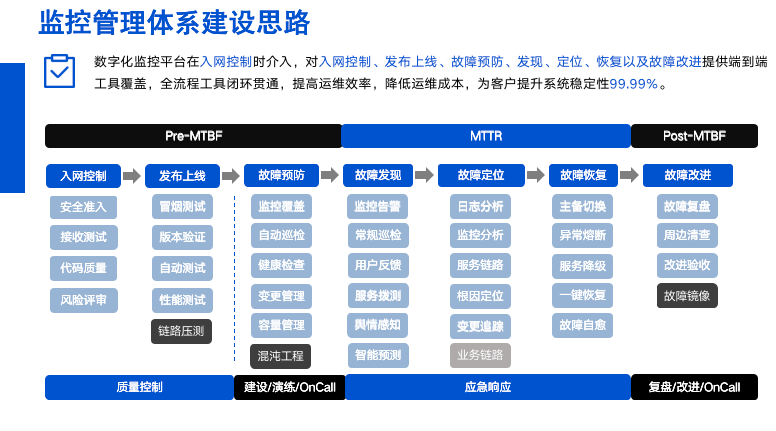
我们在故障发生的时候通过智能告警、用户反馈、拨测感知预测等方式,缩短故障。发现事件之后,会通过分析日志,告警服务链路进行快速的系统级别故障根因定位。然后再通过变更追踪。分清故障是否是因为做了配置变更操作导致的全国性问题。
对于业务层面的监控我们现阶段是通过核心业务量加量等方式进行,影响判断。对于每一种核心业务链路的监控,我们现在是还在推进建设中,并没有建设完全。因为我们运营商的业务是非常复杂的,建设业务链路的难度也很大。每种业务的链路可能涉及多个部门,多个系统,甚至跨集团和公司。
监控管理体系建设实践案例

全层级监控体系支持跨数据中心多云分布式监控,实现从业务到触点、服务、组件、云平台、基础资源的全层级指标数据互联互通,制定346项全层级监控指标标准规范,统一接入标准,提供全层级监控能力。
统一生产运营入口,运维工具一点使用,PC+移动多终端处理,工具共建、能力共享、协同研发,生产运营工作台采用苹果App Store仓库模式,实现“平台+应用”快速能力交付,构建“企业运维生态”。
智能监控告警平台提供IaaS、PaaS、SaaS各层级监控能力,实现多层级运维数据互通,支持全流程可视化配置,多渠道告警通知,工单闭环管理,用户快速实现监控接入,为系统日常生产运行提供保障。
通过探针非侵入式采集,实现调用链实时追踪、全层级故障根因定位。支持多租户、多系统接入、支撑跨数据中心、跨云平台、跨系统服务链路拓扑、告警配置、多维根因定位分析,服务耗时分析等功能。

这是浏览器监控和APP性能监控的情况。
浏览器监控:JS埋点,采集用户访问过程性能指标,获取浏览器端的真实用户行为与体验数据,包括页面加载、点击、弹窗、JS报错、AJAX等用户全轨迹跟踪,通过大数据分析,应用于故障定位、安全分析、终端分析、感知分析、异常分析等场景。
APP性能监控:SDK探针,深度剖析APP应用端服务性能指标,针对响应时长、错误率、崩溃率、分布区域等指标,采用行业标准定义及综合考评模型,准确评估应用健康、性能分析、错误定位、APP卡顿、运营分析等服务能力。
依托全层级指标数据,全层级链路调用,自研云原生CMDB,以及丰富的故障知识库,以服务层为故障起点进行纵向串联,配以规则+AI的能力实现全层级一键智能故障诊断。
关键点:耐着性子一个组件一个组件弄,一个故障场景一个故障场景弄,AI能力是辅助,故障库和专家是关键财富。

上者治未病,意思就是接入系统后能提早发现自己的问题,及时解决系统的隐患,提高系统的稳定性。依托全层级监控体系,可以构建故障预防产品-亚健康检查,自2022年1月起,我们对内部某一核心系统,历经17周,系统全层级日均高风险问题项个数:服务层112降至2,组件层246降至16,资源层75降至1。
关键点:评分与趋势,闭环运营管理
故障治理与改进

我们现在在用的故障闭环管理的流程。我们在进行事件识别。然后通过外呼钉钉功能,一键拉会。快速召集人手解决问题。然后进行事件上报。那在故障事中呢,我们是秉承先抢通后修复的原则进行故障处理。故障恢复之后,要求在48小时内进行事件的复盘,分期的,后面还要继续跟踪,将每次故障陈列为有效资产。在故障没有发生的时候,我们会让各系统进行一个应急预案的填写。
然后定期的去展开应急演练,模拟故障发生的时候,处理流程是我们故障管理线上化的一些案例。实现故障事前、事中、事后全流程线上闭环管理,提升故障管理质量和效率,降低故障时长及次数,从而提升业务连续可用率。
答疑互动-摘录
如何在海量的日志中找出关键的问题?
海量日志,我们处理链路的规模非常大,没有说是直接针对海量日志去进行分析,再进行故障定位,我们实际上的做法就是先通过根因定位到大致的范围之后,再去看这个服务的异常日志情况。第二种是针对浏览器监控。比方说弹窗日志,可以借助一些ai算法,去提取出它的这个日志模板。然后去做一些突变性的分期去看浏览器的异常。我们的就是日志处理大概是这么一个思路。并不是是直接通过海量日志去看根本原因。
普罗米修斯采集的两万个点。大概多少指标?是存储在普罗米修斯自己的tsdb里面吗?
是的,我们指标的话都是存在这个普罗米修斯里面的。两万多个监控点其实是根据经验去总结出来的346项,这个指标规范,然后各系统去看它涉及到的中间件,组件,根据这个规范去接入,然后去配置告警。我们对于所有的这个指标,其实都是在普罗米修斯进行管理的。
多租户是逻辑多租还是物理多租?
一种逻辑上的多租户就比方说是一个系统或者多个系统,分配到一个逻辑上面的一个租户底下,然后通过租户的关系,接入到我们的系统里去做一些数据上的这个隔离,比方说采集器的隔离,我靠近配置的隔离,以及大屏展示的一些隔离操作。
调用链数据是存在哪里的?
我们的调用链分为这个明细指标,还有聚合指标,所有的指标都是存在这里,明细的指标实际上是分数据中心去处理的,对于聚合指标,我们是统一的汇总到资源池里面进行存储的。
云原生的CMDB是怎么做的数据?如何做生命周期管理?
基本上是靠逐年的人工介入的梳理,包括从系统链路拓扑上面得到的这些信息进行录入,逐步形成建起来的cmdb的能力。
UGeek大咖说大厂可观测系列往期回顾:UGeek大咖说第九期【顺丰专场】
